
Introduction
Let’s face it: we’ve all had our “epic failure” moments in coding - those times when our well-intentioned plans hilariously backfired. Maybe you accidentally wiped out a database in production (oops!) or logged sensitive user data in plain text for weeks without realizing it. While these moments sting in the short term, they’re also invaluable learning experiences.
For this tutorial, we’ve taken inspiration from our favorite blunders and are building a system to capture those lessons permanently. Because if we’ve learned anything, it’s this: writing down your mistakes is the first step toward not repeating them.

And since we’re no strangers to a good laugh (and a little self-deprecation), here are some of our classics - examples that will help you get a sense of what our system will capture and persist at the end of this tutorial:
[
{
"failureID": "001",
"taskAttempted": "deploying a feature on Friday at 4:59 p.m.",
"whyItFailed": "triggered a cascade of unexpected errors",
"lessonsLearned": ["never deploy on a Friday afternoon"]
},
{
"failureID": "002",
"taskAttempted": "refactoring the codebase without tests",
"whyItFailed": "introduced numerous bugs and broke the entire application",
"lessonsLearned": ["always write tests before refactoring", "never assume the code will work without testing"]
}
]Summary of What We've Achieved So Far
In the first part of our tutorial, we set up a foundational serverless API on AWS. We created a Lambda function to handle "epic failure" submissions, deployed it with Terraform, and exposed it via API Gateway. While the Lambda logged failures in the console, it lacked persistence and a way to manage data beyond creation.
Part 2: Adding Persistence with DynamoDB
In this continuation, we’ll elevate our project by integrating DynamoDB as the database layer. We'll add two new endpoints for:
- Deleting a failure by its ID.
- Fetching all failures persisted in the database.
Moreover, our Terraform definitions will grow to include a DynamoDB table, IAM permissions for Lambda functions to operate on it, and the required updates to our API Gateway integration with the new Lambdas.
DynamoDB
AWS DynamoDB is a fully managed NoSQL database service designed to handle key-value and document-based data. It's highly scalable, providing consistent, single-digit millisecond latency for applications of any size. DynamoDB is ideal for use cases like real-time analytics, IoT, and mobile backends, where fast and predictable performance is critical. It also offers features like automatic scaling, built-in security, and multi-region replication, making it a reliable choice for storing and querying application data in the cloud.
High-Level Architecture
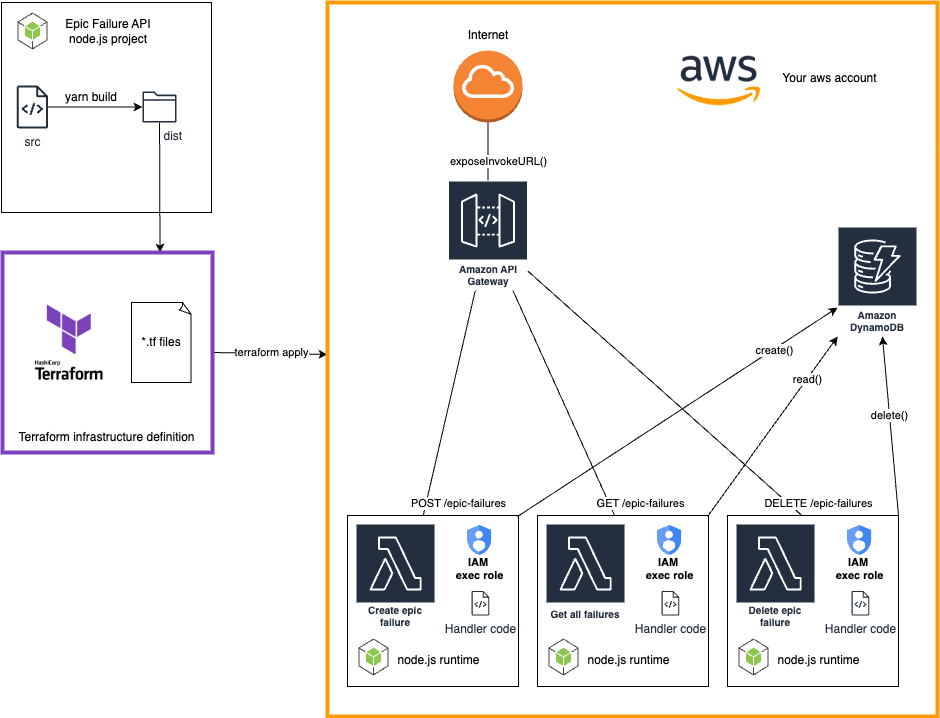
The source code for this part is available in the GitHub repository in the 102 directory. However, we strongly recommend following the tutorial to understand the concepts and steps involved, starting from the codebase created in the first [101] part.
Expanding the Node.js Application
DynamoDB service
First, let’s extend the backend code. We need to develop a DynamoDB service that will handle the integration with the database. We will use the AWS SDK npmjs packages to interact with DynamoDB. We will add the following packages to our project:
yarn add @aws-sdk/client-dynamodb @aws-sdk/util-dynamodbNow, let's create the service interface with the necessary method declarations in epicfailure-api/src/services/IDynamoDBService.ts and implement the service class in epicfailure-api/src/services/DynamoDBService.ts.
// epicfailure-api/src/shared-layer/services/IDynamoDBService.ts
// This file defines the IDynamoDBService interface, which specifies the methods for interacting with AWS DynamoDB.
import type { IEpicFailure } from "src/models/EpicFailure";
export interface IDynamoDBService {
addEpicFailure(failureID: string, taskAttempted: string, whyItFailed: string, lessonsLearned: string[]): Promise<void>;
getEpicFailures(): Promise<IEpicFailure[]>;
deleteEpicFailure(failureID: string): Promise<void>;
}
// epicfailure-api/src/shared-layer/services/DynamoDBService.ts
// This file defines the DynamoDBService class, which implements the IDynamoDBService interface.
// The class provides methods for interacting with AWS DynamoDB, including adding, retrieving, and deleting epic failure records.
// It uses the AWS SDK for JavaScript to communicate with DynamoDB and the AWS SDK utilities for marshalling and unmarshalling data.
import { DynamoDBClient, PutItemCommand, DeleteItemCommand, ScanCommand } from '@aws-sdk/client-dynamodb';
import { marshall, unmarshall } from '@aws-sdk/util-dynamodb';
import { IDynamoDBService } from './IDynamoDBService';
import type { IEpicFailure } from '../models/EpicFailure';
class DynamoDBService implements IDynamoDBService {
private client: DynamoDBClient;
constructor() {
this.client = new DynamoDBClient({ region: process.env.AWS_REGION });
}
async addEpicFailure(failureID: string, taskAttempted: string, whyItFailed: string, lessonsLearned: string[]): Promise<void> {
const params = {
TableName: process.env.DYNAMODB_TABLE_NAME,
Item: marshall({
failureID,
taskAttempted,
whyItFailed,
lessonsLearned,
}),
};
const command = new PutItemCommand(params);
await this.client.send(command);
}
async getEpicFailures(): Promise<IEpicFailure[]> {
const params = {
TableName: process.env.DYNAMODB_TABLE_NAME,
};
const command = new ScanCommand(params);
const response = await this.client.send(command);
return (response.Items || []).map((item) => unmarshall(item) as IEpicFailure);
}
async deleteEpicFailure(failureID: string): Promise<void> {
const params = {
TableName: process.env.DYNAMODB_TABLE_NAME,
Key: { failureID: { S: failureID } },
};
const command = new DeleteItemCommand(params);
await this.client.send(command);
}
}
export default DynamoDBService;As you can see, we are referring to the environment variables AWS_REGION and DYNAMODB_TABLE_NAME in the DynamoDBService class. We will need to set these variables in the Lambda function runtimes. We will configure DYNAMODB_TABLE_NAME in the Terraform configuration later, while AWS_REGION is automatically set in the Lambda execution environment.
Integrate existing create epic failure Lambda with DynamoDB service
In the previous post, we created a Lambda function to handle the creation of epic failures. Now, we need to integrate it with the DynamoDB service. To achieve that we will modify the createEpicFailure function in the epicfailure-api/src/handlers/create-epic-failure-handler.ts.
// epicfailure-api/src/handlers/create-epic-failure-handler.ts
// This file defines the AWS Lambda handler for creating an epic failure record in DynamoDB.
// It imports necessary services and models, parses the incoming request, validates the input,
// creates an EpicFailure object, and uses DynamoDBService to store the record in DynamoDB.
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
import * as Joi from 'joi';
import EpicFailure, { IEpicFailure } from '../models/EpicFailure';
import DynamoDBService from '../services/DynamoDBService';
const dynamoDBService = new DynamoDBService();
const epicFailureSchema = Joi.object<IEpicFailure>({
failureID: Joi.string().required(),
taskAttempted: Joi.string().required(),
whyItFailed: Joi.string().required(),
lessonsLearned: Joi.array().items(Joi.string()).required(),
});
const createEpicFailureHandler = async (event: APIGatewayProxyEvent): Promise<APIGatewayProxyResult> => {
console.log('Event: ', event);
// Parse the request body
const requestBody = JSON.parse(event.body || '{}');
// Validate the request body against the schema
const { error, value } = epicFailureSchema.validate(requestBody);
if (error) {
return {
statusCode: 400,
body: JSON.stringify({ message: 'Invalid request body', error: error.details[0].message }),
};
}
const { failureID, taskAttempted, whyItFailed, lessonsLearned } = value as IEpicFailure;
const epicFailure = new EpicFailure(failureID, taskAttempted, whyItFailed, lessonsLearned);
try {
await dynamoDBService.addEpicFailure(epicFailure.failureID, epicFailure.taskAttempted, epicFailure.whyItFailed, epicFailure.lessonsLearned);
return {
statusCode: 201,
body: JSON.stringify({ message: 'Epic failure created successfully', epicFailure }),
};
} catch (error) {
console.error('Error creating epic failure:', error);
return {
statusCode: 500,
body: JSON.stringify({ message: 'Failed to create epic failure', error: error.message }),
};
}
};
exports.handler = createEpicFailureHandler;Add a new Lambda function to get all epic failures
Once the epic failures are stored in DynamoDB, we can retrieve them through the getEpicFailures method provided by the DynamoDB service.
We will create a new Lambda function to handle this operation. The function will be defined in the epicfailure-api/src/handlers/get-all-failures-handler.ts file.
// epicfailure-api/src/handlers/get-all-failures-handler.ts
// This file defines the AWS Lambda handler for retrieving all epic failure records from DynamoDB.
// It imports necessary services and models, and uses DynamoDBService to fetch all records from DynamoDB.
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
import type { IEpicFailure } from '../models/EpicFailure';
import DynamoDBService from '../services/DynamoDBService';
const dynamoDBService = new DynamoDBService();
const getAllFailuresHandler = async (event: APIGatewayProxyEvent): Promise<APIGatewayProxyResult> => {
console.log('Event: ', event);
try {
const epicFailures: IEpicFailure[] = await dynamoDBService.getEpicFailures();
return {
statusCode: 200,
body: JSON.stringify({ epicFailures }),
};
} catch (error) {
console.error('Error getting epic failures:', error);
return {
statusCode: 500,
body: JSON.stringify({ message: 'Failed to get epic failures', error: error.message }),
};
}
};
exports.handler = getAllFailuresHandler;Add a new Lambda function to delete an epic failure
We will create another Lambda function to handle the deletion of an epic failure record. The function will be defined in the epicfailure-api/src/handlers/delete-epic-failure-handler.ts file.
// epicfailure-api/src/handlers/delete-epic-failure-handler.ts
// This file defines the AWS Lambda handler for deleting an epic failure record from DynamoDB.
// It imports necessary services, parses the incoming request to extract the failureID,
// and uses DynamoDBService to delete the record from DynamoDB.
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
import DynamoDBService from '../services/DynamoDBService';
const dynamoDBService = new DynamoDBService();
const deleteEpicFailureHandler = async (event: APIGatewayProxyEvent): Promise<APIGatewayProxyResult> => {
console.log('Event: ', event);
const { failureID } = JSON.parse(event.body || '{}');
if (!failureID) {
return {
statusCode: 400,
body: JSON.stringify({ message: 'failureID is required' }),
};
}
try {
await dynamoDBService.deleteEpicFailure(failureID);
return {
statusCode: 200,
body: JSON.stringify({ message: 'Epic failure deleted successfully' }),
};
} catch (error) {
console.error('Error deleting epic failure:', error);
return {
statusCode: 500,
body: JSON.stringify({ message: 'Failed to delete epic failure', error: error.message }),
};
}
};
exports.handler = deleteEpicFailureHandler;
Updating Terraform Definitions
We’ll now modify Terraform to include DynamoDB and configure deployment of our new Lambda functions.
A Brief Note on DynamoDB Table Design
Before creating a DynamoDB table, it’s important to think about how your application will use it. DynamoDB requires you to define a primary key, which is used to uniquely identify each item in the table. There are two types of primary keys:
- Partition Key (hash key): A single attribute that uniquely identifies an item. This is mandatory for all tables.
- Composite Key (partition key + sort key): Adds a sort key to the partition key, allowing multiple items with the same partition key to be organized and queried together.
DynamoDB also supports secondary indexes, which are optional and allow querying the table using attributes other than the primary key:
- Global Secondary Index (GSI): A flexible query option using an alternate partition and/or sort key.
- Local Secondary Index (LSI): Adds a sort key to an existing partition key but must be defined during table creation.
For this tutorial, we’re keeping things simple with a single partition key, failureID. This key will uniquely identify each failure record in our table. You can extend the table later with secondary indexes if your application needs more complex query patterns.
Define DynamoDB Module
Create a new directory dynamodb in the terraform/modules directory and add the following files:
# terraform/modules/dynamodb/main.tf
# This Terraform configuration defines the following AWS DynamoDB resource:
# 1. DynamoDB Table (aws_dynamodb_table): Creates a DynamoDB table with the specified name, billing mode, hash key, and tags.
resource "aws_dynamodb_table" "epic_failures" {
name = var.dynamo_table_name
billing_mode = "PAY_PER_REQUEST"
hash_key = "failureID"
attribute {
name = "failureID"
type = "S"
}
tags = {
Name = "${var.dynamo_table_name}"
}
}
The main.tf file defines a DynamoDB table with the specified name, billing mode, and hash key.
This configuration defines a DynamoDB table with the failureID as the partition key. In this scenario:
- Hash Key (failureID): Acts as the unique identifier for each record.
- Attribute Type (S): Indicates the data type is a string.
You can later add attributes to support secondary indexes for additional query capabilities, depending on your application’s needs.
# terraform/modules/dynamodb/variables.tf
# This Terraform configuration defines the following input variables of the module:
# 1. aws_region: The AWS region to deploy resources.
# 2. dynamo_table_name: The name of the Epic Failures DynamoDB table.
variable "aws_region" {
description = "The AWS region to deploy resources"
type = string
}
variable "dynamo_table_name" {
description = "The name of the Epic Failures DynamoDB table"
} The variables.tf file defines input variables necessary for the module's configuration.
Add IAM Permissions for DynamoDB Access
To allow the Lambda functions to interact with the DynamoDB table, we need to create a new IAM policy and attach it to the Lambda execution role.
In file: modules/lambda-api/main.tf add the following resources:
resource "aws_iam_policy" "lambda_dynamodb_policy" {
name = "lambda_dynamodb_policy"
description = "IAM policy for Lambda to access DynamoDB"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = [
"dynamodb:PutItem",
"dynamodb:Scan",
"dynamodb:DeleteItem"
]
Resource = [
"arn:aws:dynamodb:${var.aws_region}:${data.aws_caller_identity.current.account_id}:table/${var.dynamo_table_name}",
]
}
]
})
}
resource "aws_iam_role_policy_attachment" "lambda_dynamodb_policy_attachment" {
role = aws_iam_role.lambda_role_exec.name
policy_arn = aws_iam_policy.lambda_dynamodb_policy.arn
}The existing Lambda role policy is updated to include permissions for DynamoDB actions such as PutItem, Scan, DeleteItem on the specified DynamoDB table. The list of allowed actions is limited to the minimum required for the Lambda functions to interact with the table. This is a good practice to follow the principle of least privilege.
Passing Environment Variables to Lambda Functions
The DynamoDBService makes use of environment variables to access the DynamoDB table name. We need to update the Lambda function environment variables to include these values. In order to do that we are going to add shared environments object to the modules/lambda-api/main.tf file.
locals {
shared_env_vars = {
DYNAMODB_TABLE_NAME = var.dynamo_table_name
}
}Then we need to update the Lambda function resource definitions to include the environment variables. In file modules/lambda-api/lambda-handler-create-epic-failure.tf extend the aws_lambda_function resource definition with the environment block:
resource "aws_lambda_function" "lambda_create_epic_failure" {
function_name = "${var.lambda_function_name_prefix}-create-epic-failure"
runtime = "nodejs18.x"
handler = "create-epic-failure-handler.handler"
role = aws_iam_role.lambda_role_exec.arn
filename = data.archive_file.create_epic_failure_lambda_zip.output_path
source_code_hash = data.archive_file.create_epic_failure_lambda_zip.output_base64sha256
environment {
variables = local.shared_env_vars
}
}Define Lambda function deployments and API Gateway integration for GET and DELETE operations
Create two new files in the lambda-api module: lambda-handler-get-all-failures.tf and lambda-handler-delete-epic-failure.tf. Use code from create epic failure Lambda function as a template and modify it to fit the requirements of the new functions.
get-all-failures-handler.tsshould be a GET method under the path/epic-failures.delete-epic-failure-handler.tsshould be a DELETE method under the path/epic-failures.
In case you have any issues with the code, you can find the complete code in the GitHub repository.
Enable dynamodb module in the root main.tf file
In the root main.tf file, enable the DynamoDB module by adding the following code:
module "dynamodb" {
source = "./modules/dynamodb"
aws_region = var.aws_region
dynamo_table_name = var.dynamo_table_name
}We also need to extend the lambda-api module intstantiation providing it with the DynamoDB table name variable:
module "lambda-api" {
source = "./modules/lambda-api"
aws_region = var.aws_region
dynamo_table_name = var.dynamo_table_name
api_gateway_id = module.apigateway.api_gateway_id
api_gateway_execution_arn = module.apigateway.api_gateway_execution_arn
}Extend variables
Update the root variables.tf and modules/lambda-api/variables.tf file to include the new variable:
variable "dynamo_table_name" {
description = "The name of the DynamoDB table"
default = "epic-failures"
}Deploying and Testing
Once the configurations are in place, build and deploy the updated code and infrastructure. You can use single yarn script that combines bundling handlers' code script and the terraform apply command.
cd epicfailure-api && yarn build-and-deployIn the terminal, export the INVOKE_URL from the build and deploy script output.
export INVOKE_URL="https://<api-id>.execute-api.<region>.amazonaws.com/<stage>"Create an epic failure records
Use the curl POST request to create epic failure record.
curl -X POST \
${INVOKE_URL}/epic-failures \
-H "Content-Type: application/json" \
-d '{
"failureID": "001",
"taskAttempted": "deploying a feature on Friday at 4:59 p.m.",
"whyItFailed": "triggered a cascade of unexpected errors",
"lessonsLearned": ["never deploy on a Friday afternoon"]
}'curl -X POST \
${INVOKE_URL}/epic-failures \
-H "Content-Type: application/json" \
-d '{
"failureID": "002",
"taskAttempted": "refactoring the codebase without tests",
"whyItFailed": "introduced numerous bugs and broke the entire application",
"lessonsLearned": ["always write tests before refactoring", "never assume the code will work without testing"]
}'Get all epic failure records
curl -X GET \
${INVOKE_URL}/epic-failures \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${ID_TOKEN}"Delete an epic failure record
curl -X DELETE \
${INVOKE_URL}/epic-failures \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${ID_TOKEN}" \
-d '{
"failureID": "001"
}'Get all epic failure records to verify the deletion
curl -X GET \
${INVOKE_URL}/epic-failures \
-H "Content-Type: application/json" \
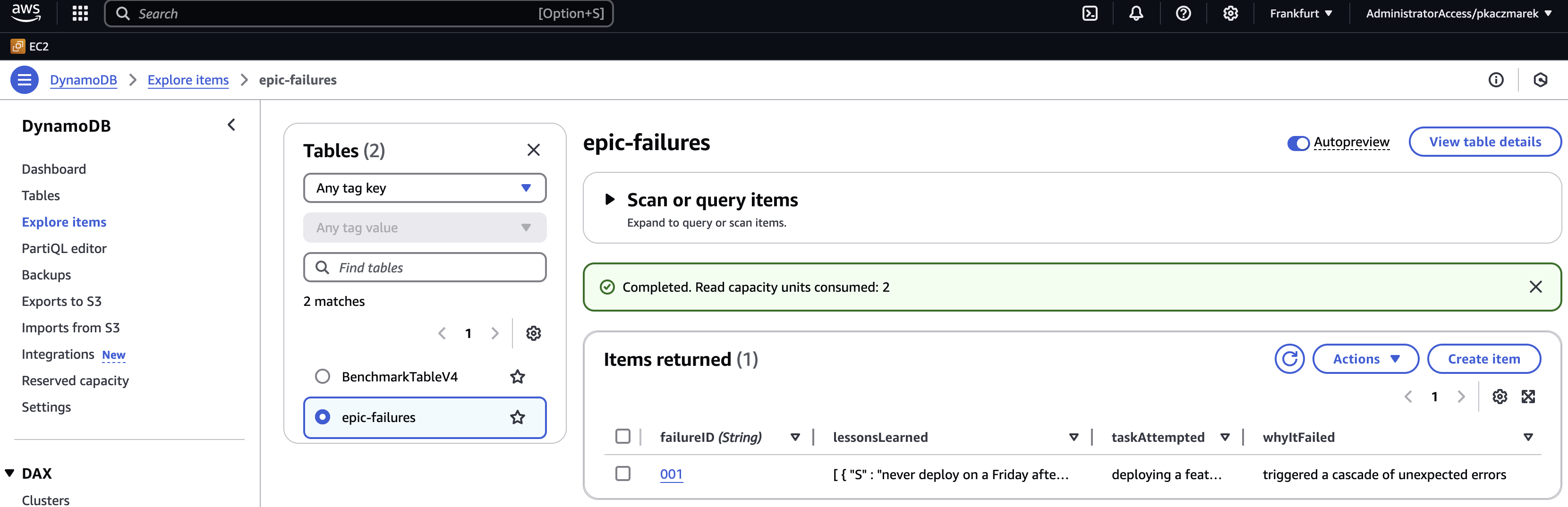
-H "Authorization: Bearer ${ID_TOKEN}"Run all the commands in the sequence above to create, retrieve, and delete epic failure records. Verify that the operations are successful and the data is persisted in the DynamoDB table. You can also browse table records in the AWS Management Console to confirm the data is stored correctly.
Wrapping Up
By completing this part, you’ve added persistence and management capabilities to your serverless API. You’ve also deepened your understanding of integrating AWS services like DynamoDB into a serverless architecture. In the next part, we’ll dive into securing these endpoints with AWS Cognito. Stay tuned!




![[103] Securing Your Terraform Serverless API with Cognito](https://cdn.prod.website-files.com/67362585a7df1c57acedee7a/67600b4f8195ac0a3e9ee894_y804x.jpg)
![[101] Launch Your Own Secure Serverless API on AWS with Terraform](https://cdn.prod.website-files.com/67362585a7df1c57acedee7a/67371f0afb60a80f2b2c2a70_terraforming.jpg)







